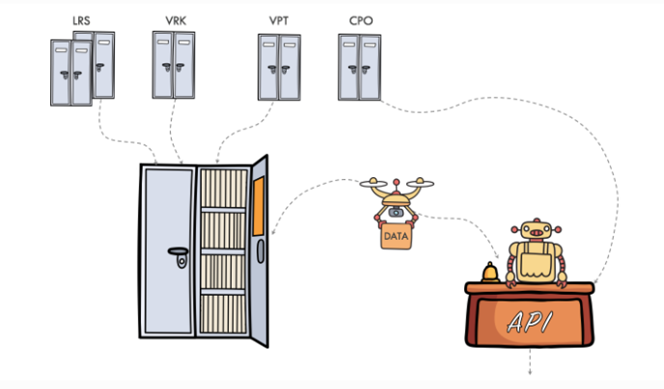
Concept of data opening on demand
We have concluded that data must be opened in a demand driven way and the data with highest demand must be opened first. But the problem is that we do not fully know what the demand is. From other side a potential data user does not know what data are available. This is a closed circle. While we were thinking about that, we realized also, that nobody in our country knows in detail what data we have. In fact, we do not have fine grained details of existing data at the level of individual data fields. We only know abstract dataset titles and descriptions.
To escape this closed circle of ignorance a decision has been made to start with a full and detailed inventory of existing data and share the results with potential data users to get early feedback and only then proceed with opening the data. In this case, primary data source must be ready for quick automotive transformation to open set. Consequently, a full and detailed inventory of existing data sources must be done first, and the next – IT solutions must be in place:
• a common set of tools used to automate process of opening the data from primary data sources into a service designed for data publishing,
• a data publishing service to access the data in bulk or as individual data objects, in various data formats via flexible and unified API for all data from all data providers.
Today we already developed and test following tools for institutions to use:
• a tool to automate process of full and detailed data inventory using standardized, human and machine-readable data inventory tables, containing all the metadata needed to automate the whole process of opening the data.
• a tool to detect personal data recognition and indexing to the inventory table.
• an automated data extraction tool, that can read metadata from inventory tables and transfer data from primary data sources to a data publishing service.
Benefits of the solution:
• metadata available in the inventory tables can be used to update DCAT metadata in a data catalog or to build a data publishing service that can accept data described in inventory tables and provide an API for data publishing in various formats.
• data inventory tables can be attached to datasets in open data catalogue to give data users a detailed information about the data in detail about all data fields, their types, relations and descriptions;
• data users having such inventory tables, can ask very specific questions about missing data fields or insufficient data maturity level, this way communication between data users and providers becomes much more efficient and precise.
As a side effect of a such detailed data inventory, we expect to have a comprehensive detailed metadata about existing data sources in Lithuania.